AI proxy
The Braintrust AI Proxy is a powerful tool that enables you to access models from OpenAI, Anthropic, Google, AWS, Mistral, and third-party inference providers like Together which offer open source models like LLaMa 3 — all through a single, unified API.
With the AI proxy, you can:
- Simplify your code by accessing many AI providers through a single API.
- Reduce your costs by automatically caching results when possible.
- Increase observability by optionally logging your requests to Braintrust.
Best of all, the AI proxy is free to use, even if you don't have a Braintrust account.
To read more about why we launched the AI proxy, check out our blog post announcing the feature.
The AI proxy is free for all users. You can access it without a Braintrust account by using your API key from any of the supported providers. With a Braintrust account, you can use a single Braintrust API key to access all AI providers.
Quickstart
The Braintrust Proxy is fully compatible with applications written using the
OpenAI SDK. You can get started without making any code changes. Just set the
API URL to https://api.braintrust.dev/v1/proxy.
Try running the following script in your favorite language, twice:
Anthropic users can pass their Anthropic API key with a model such as
claude-3-5-sonnet-20240620.
The second run will be significantly faster because the proxy served your request from its cache, rather than rerunning the AI provider's model. Under the hood, your request is served from a Cloudflare Worker that caches your request with end-to-end encryption.
Key features
The proxy is a drop-in replacement for the OpenAI API, with a few killer features:
- Automatic caching of results, with configurable semantics
- Interopability with other providers, including a wide range of open source models
- API key management
Caching
The proxy automatically caches results, and reuses them when possible. Because the proxy runs on the edge, you can expect cached requests to be returned in under 100ms. This is especially useful when you're developing and frequently re-running or evaluating the same prompts many times.
The cache follows the following rules:
- There are three caching modes:
auto(default),always,never. - In
automode, requests are cached if they havetemperature=0or theseedparameter set. - In
alwaysmode, requests are cached as long as they are one of the supported paths (/chat/completions,/completions, or/embeddings) - In
nevermode, the cache is never read or written to.
You can set the cache by passing the x-bt-use-cache header to your request. For example, to always use the cache,
Encryption
We use AES-GCM to encrypt the cache, using a key derived from your API key. Currently, results are cached for 1 week.
This design ensures that the cache is only accessible to you, and that we cannot see your data. We also do not store or log API keys.
Because the cache's encryption key is your API key, cached results are scoped to an individual user. However, Braintrust customers can opt-into sharing cached results across users within their organization.
Supported models
The proxy supports over 100 models, including popular models like GPT-4o, Claude 3.5 Sonnet, Llama 2, and Gemini Pro. It also supports third-party inference providers, including the Azure OpenAI Service, Amazon Bedrock, and Together AI. See the full list of models and providers at the bottom of this page.
We are constantly adding new models. If you have a model you'd like to see supported, please let us know!
Supported protocols
HTTP-based models
The proxy receives HTTP requests in the OpenAI API schema, automatically translating OpenAI requests into various providers' APIs. That means you can interact with other providers like Anthropic by using OpenAI client libraries and API calls.
However, the proxy does not currently accept requests in other providers' API schemas. That means, for example, you cannot use the Anthropic SDKs with the proxy. If you are interested in using other providers' APIs, please let us know.
WebSocket-based models
The proxy supports the OpenAI Realtime API at the
/realtime endpoint. To use the proxy with the OpenAI Reference
Client, set the url to
https://braintrustproxy.com/v1/realtime when constructing the
RealtimeClient or RealtimeAPI
classes:
For developers trying out the OpenAI Realtime Console sample app, we maintain a fork that demonstrates how to modify the sample code to use the proxy.
You can continue to use your OpenAI API key as usual if you are creating the
RealtimeClient in your backend. If you would like to run the RealtimeClient
in your frontend or in a mobile app, we recommend passing temporary
credentials to your frontend to
avoid exposing your API key.
API key management
The proxy allows you to use either a provider's API key or your Braintrust API key. If you use a provider's API key, you can use the proxy without a Braintrust account to take advantage of low-latency edge caching (scoped to your API key).
If you use a Braintrust API key, you can access multiple model providers through the proxy and manage all your API keys in one place. To do so, sign up for an account and add each provider's API key on the AI providers page in your settings.

Custom models
If you have custom models as part of your OpenAI or other accounts, you can use
them with the proxy by adding a custom provider. For example, if you have a
custom model called gpt-3.5-acme, you can add it to your
organization settings by navigating to
Settings > Organization:
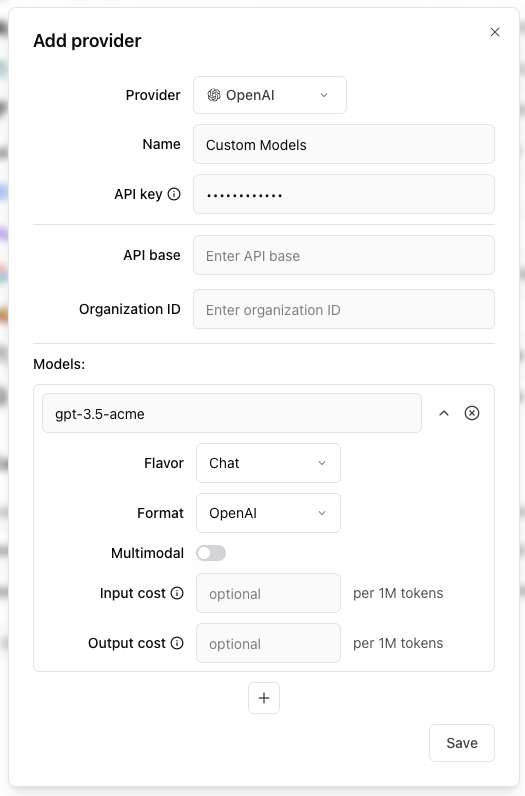
Each custom model must have a flavor (chat or completion) and format (openai, anthropic, google, window or js). Additionally, they can
optionally have a boolean flag if the model is multimodal and an input cost and output cost, which will only be used to calculate and display estimated
prices for experiment runs.
Specifying an org
If you are part of multiple organizations, you can specify which organization to use by passing the x-bt-org-name
header in the SDK:
Temporary credentials for end user access
A temporary credential converts your Braintrust API key (or model provider API key) to a time-limited credential that can be safely shared with end users.
- Temporary credentials can also carry additional information to limit access to a particular model and/or enable logging to Braintrust.
- They can be used in the
Authorizationheader anywhere you'd use a Braintrust API key or a model provider API key.
Use temporary credentials if you'd like your frontend or mobile app to send AI requests to the proxy directly, minimizing latency without exposing your API keys to end users.
Issue temporary credential in code
You can call the /credentials endpoint from a privileged
location, such as your app's backend, to issue temporary credentials. The
temporary credential will be allowed to make requests on behalf of the
Braintrust API key (or model provider API key) provided in the Authorization
header.
The body should specify the restrictions to be applied to the temporary
credentials as a JSON object. Additionally, if the logging key is present, the
proxy will log to Braintrust any requests made with this temporary credential.
See the /credentials API spec for details.
The following example grants access to gpt-4o-realtime-preview-2024-10-01 on
behalf of the key stored in the BRAINTRUST_API_KEY environment variable for 10
minutes, logging the requests to the project named "My project."
Issue temporary credential in browser
You can also generate a temporary credential using the form below:
import { OpenAI } from "openai";
const client = new OpenAI({
baseURL: "https://api.braintrust.dev/v1/proxy",
apiKey: "YOUR_TEMPORARY_CREDENTIAL",
// It is safe to store temporary credentials in the browser because they have
// limited lifetime and access.
dangerouslyAllowBrowser: true,
});
async function main() {
const response = await client.chat.completions.create({
model: "gpt-4o-mini",
messages: [{ role: "user", content: "What is a proxy?" }],
});
console.log(response.choices[0].message.content);
}
main();
Inspect temporary credential grants
The temporary credential is formatted as a JSON Web Token (JWT).
You can inspect the JWT's payload using a library such as
jsonwebtoken or a web-based tool like JWT.io to
determine the expiration time and granted models.
Do not modify the JWT payload. This will invalidate the signature. Instead,
issue a new temporary credential using the /credentials endpoint.
Load balancing
If you have multiple API keys for a given model type, e.g. OpenAI and Azure for gpt-3.5-turbo, the proxy will
automatically load balance across them. This is a useful way to work around per-account rate limits and provide
resiliency in case one provider is down.
You can setup endpoints directly on the secrets page in your Braintrust account by adding endpoints:

Advanced configuration
The following headers allow you to configure the proxy's behavior:
x-bt-use-cache:auto | always | never. See Cachingx-bt-use-creds-cache:auto | always | never. Similar tox-bt-use-cache, but controls whether to cache the credentials used to access the provider's API. This is useful if you are rapidly tweaking credentials and don't want to wait ~60 seconds for the credentials cache to expire.x-bt-org-name: Specify if you are part of multiple organizations and want to use API keys/log to a specific org.x-bt-endpoint-name: Specify to use a particular endpoint (by its name).
Integration with Braintrust platform
Several features in Braintrust are powered by the proxy. For example, when you create a playground, the proxy handles running the LLM calls. Similarly, if you create a prompt, when you preview the prompt's results, the proxy is used to run the LLM. However, the proxy is not required when you:
- Run evals in your code
- Load prompts to run in your code
- Log traces to Braintrust
If you'd like to use it in your code to help with caching, secrets management, and other features, follow the instructions above to set it as the base URL in your OpenAI client.
Self-hosting
If you're self-hosting Braintrust, your API service (serverless functions or containers) contain a built-in proxy that runs within your own environment. See the self-hosting docs for more information on how to set up self-hosting.
Open source
The AI proxy is open source. You can find the code on GitHub.
Appendix
List of supported models and providers
- gpt-4o (openai, azure)
- gpt-4o-mini (openai, azure)
- gpt-4o-2024-08-06 (openai, azure)
- gpt-4o-2024-05-13 (openai, azure)
- gpt-4o-mini-2024-07-18 (openai, azure)
- o1-preview (openai, azure)
- o1-mini (openai, azure)
- o1-preview-2024-09-12 (openai, azure)
- o1-mini-2024-09-12 (openai, azure)
- gpt-4-turbo (openai, azure)
- gpt-4-turbo-2024-04-09 (openai, azure)
- gpt-4-turbo-preview (openai, azure)
- gpt-4-0125-preview (openai, azure)
- gpt-4-1106-preview (openai, azure)
- gpt-4 (openai, azure)
- gpt-4-0613 (openai, azure)
- gpt-4-0314 (openai, azure)
- gpt-3.5-turbo-0125 (openai, azure)
- gpt-3.5-turbo (openai, azure)
- gpt-35-turbo (azure)
- gpt-3.5-turbo-1106 (openai, azure)
- gpt-3.5-turbo-instruct (openai, azure)
- gpt-3.5-turbo-instruct-0914 (openai, azure)
- gpt-4-32k (openai, azure)
- gpt-4-32k-0613 (openai, azure)
- gpt-4-32k-0314 (openai, azure)
- gpt-4-vision-preview (openai, azure)
- gpt-4-1106-vision-preview (openai, azure)
- gpt-3.5-turbo-16k (openai, azure)
- gpt-35-turbo-16k (azure)
- gpt-3.5-turbo-16k-0613 (openai, azure)
- gpt-3.5-turbo-0613 (openai, azure)
- gpt-3.5-turbo-0301 (openai, azure)
- text-davinci-003 (openai, azure)
- claude-3-5-sonnet-latest (anthropic)
- claude-3-5-sonnet-20241022 (anthropic)
- claude-3-5-sonnet-20240620 (anthropic)
- claude-3-5-haiku-20241022 (anthropic)
- claude-3-haiku-20240307 (anthropic)
- claude-3-sonnet-20240229 (anthropic)
- claude-3-opus-20240229 (anthropic)
- anthropic.claude-3-5-sonnet-20241022-v2:0 (bedrock)
- anthropic.claude-3-5-sonnet-20240620-v1:0 (bedrock)
- anthropic.claude-3-haiku-20240307-v1:0 (bedrock)
- anthropic.claude-3-sonnet-20240229-v1:0 (bedrock)
- anthropic.claude-3-opus-20240229-v1:0 (bedrock)
- claude-instant-1.2 (anthropic)
- claude-instant-1 (anthropic)
- claude-2.1 (anthropic)
- claude-2.0 (anthropic)
- claude-2 (anthropic)
- meta/llama-2-70b-chat (replicate)
- mistral (ollama)
- phi (ollama)
- pplx-7b-chat (perplexity)
- pplx-7b-online (perplexity)
- pplx-70b-chat (perplexity)
- pplx-70b-online (perplexity)
- codellama-34b-instruct (perplexity)
- codellama-70b-instruct (perplexity)
- llama-3-8b-instruct (perplexity)
- llama-3-70b-instruct (perplexity)
- llama-2-13b-chat (perplexity)
- llama-2-70b-chat (perplexity)
- mistral-7b-instruct (perplexity)
- mixtral-8x7b-instruct (perplexity)
- mixtral-8x22b-instruct (perplexity)
- openhermes-2-mistral-7b (perplexity)
- openhermes-2.5-mistral-7b (perplexity)
- meta-llama/Llama-3.2-3B-Instruct-Turbo (together)
- meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo (together)
- meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo (together)
- meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo (together)
- meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo (together)
- meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo (together)
- meta-llama/Meta-Llama-3-70B (together)
- meta-llama/Llama-3-8b-hf (together)
- meta-llama/Llama-3-8b-chat-hf (together)
- meta-llama/Llama-3-70b-chat-hf (together)
- meta-llama/Llama-2-70b-chat-hf (together)
- mistralai/Mistral-7B-Instruct-v0.1 (together)
- mistralai/mixtral-8x7b-32kseqlen (together)
- mistralai/Mixtral-8x7B-Instruct-v0.1 (together)
- mistralai/Mixtral-8x7B-Instruct-v0.1-json (together)
- mistralai/Mixtral-8x22B (together)
- mistralai/Mixtral-8x22B-Instruct-v0.1 (together)
- NousResearch/Nous-Hermes-2-Yi-34B (together)
- deepseek-ai/deepseek-coder-33b-instruct (together)
- mistral-large-latest (mistral)
- pixtral-12b-2409 (mistral)
- open-mistral-nemo (mistral)
- codestral-latest (mistral)
- open-mixtral-8x22b (mistral)
- open-codestral-mamba (mistral)
- mistral-tiny (mistral)
- mistral-small (mistral)
- mistral-medium (mistral)
- llama-3.1-8b-instant (groq)
- llama-3.1-70b-versatile (groq)
- llama-3.1-405b-reasoning (groq)
- gemma-7b-it (groq)
- llama3-8b-8192 (groq)
- llama3-70b-8192 (groq)
- llama2-70b-4096 (groq)
- mixtral-8x7b-32768 (groq)
- llama3-1-8b (lepton)
- llama3-1-70b (lepton)
- llama3-1-405b (lepton)
- accounts/fireworks/models/llama-v3p2-3b-instruct (fireworks)
- accounts/fireworks/models/llama-v3p1-8b-instruct (fireworks)
- accounts/fireworks/models/llama-v3p2-11b-vision-instruct (fireworks)
- accounts/fireworks/models/llama-v3p1-70b-instruct (fireworks)
- accounts/fireworks/models/llama-v3p2-90b-vision-instruct (fireworks)
- accounts/fireworks/models/llama-v3p1-405b-instruct (fireworks)
- llama3.1-8b (cerebras)
- llama3.1-70b (cerebras)
- gemini-1.5-pro (google)
- gemini-1.5-flash (google)
- gemini-1.5-pro-002 (google)
- gemini-1.5-flash-002 (google)
- gemini-1.5-pro-latest (google)
- gemini-1.5-flash-latest (google)
- gemini-1.5-flash-8b (google)
- gemini-1.0-pro (google)
- gemini-pro (google)
- grok-beta (xAI)
We are constantly adding new models. If you have a model you'd like to see supported, please let us know!